lexograph /ˈleksəʊɡɹɑːf/ (n.)
A text document generated from digital image data
Last week, I launched a web application and a concept for photographic text generation that I have been working on for a few months. The idea came to me while working on another project, a computer generated screenplay, and I will discuss the connection in this post.
word.camera is responsive — it works on desktop, tablet, and mobile devices running recent versions of iOS or Android. The code behind it is open source and available on GitHub, because lexography is for everyone.
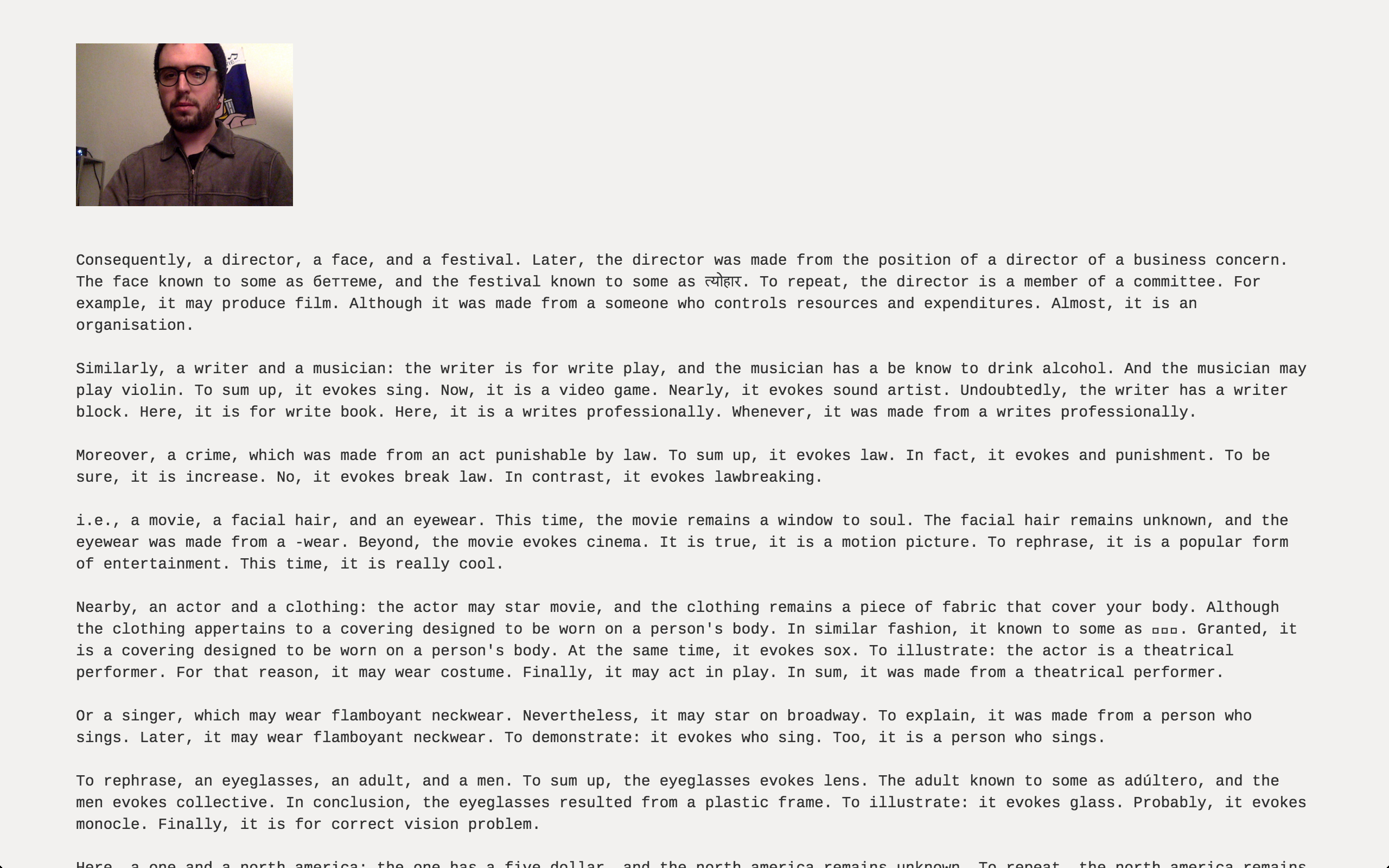
Users can share their lexographs using unique URLs. Of all this lexographs I’ve seen generated by users since the site launched (there are now almost 7,000), this one, shared on reddit’s /r/creativecoding, stuck with me the most: http://word.camera/i/7KZPPaqdP
I was surprised when the software noticed and commented on the singer in the painting behind me: http://word.camera/i/ypQvqJr6L
I was inspired to create this project while working on another project. This semester, I received a grant from the Future of Storytelling Initiative at NYU to produce a computer generated screenplay, and I had been thinking about how to generate text that’s more cohesive and realistically descriptive, meaning that it would transition between related topics in a logical fashion and describe a scene that could realistically exist (no “colorless green ideas sleeping furiously”) in order to making filming the screenplay possible . After playing with the Clarifai API, which uses convolutional neural networks to tag images, it occurred to me that including photographs in my input corpus, rather than relying on text alone, could provide those qualities. word.camera is my first attempt at producing that type of generative text.
At the moment, the results are not nearly as grammatical as I would like them to be, and I’m working on that. The algorithm extracts tags from images using Clarifai’s convolutional neural networks, then expands those tags into paragraphs using ConceptNet (a lexical relations database developed at MIT) and a flexible template system. The template system enables the code to build sentences that connect concepts together.
This project is about augmenting our creativity and presenting images in a different format, but it’s also about creative applications of artificial intelligence technology. I think that when we think about the type of artificial intelligence we’ll have in the future, based on what we’ve read in science fiction novels, we think of a robot that can describe and interact with its environment with natural language. I think that creating the type of AI we imagine in our wildest sci-fi fantasies is not only an engineering problem, but also a design problem that requires a creative approach.
I hope lexography eventually becomes accepted as a new form of photography. As a writer and a photographer, I love the idea that I could look at a scene and photograph it because it might generate an interesting poem or short story, rather than just an interesting image. And I’m not trying to suggest that word.camera is the final or the only possible implementation of that new art form. I made the code behind word.camera open source because I want others to help improve it and make their own versions — provided they also make their code available under the same terms, which is required under the GNU GPLv3 open source license I’m using. As the technology gets better, the results will get better, and lexography will make more sense to people as a worthy artistic pursuit.
I’m thrilled that the project has received worldwide attention from photography blogs and a few media outlets, and I hope users around the world continue enjoying word.camera as I keep working to improve it. Along with improving the language, I plan to expand the project by offering a mobile app and generated downloadable ebooks so that users can enjoy their lexographs offline.
